📊 临床基线数据分析:医学研究的基石与洞察之窗 🏥
🌟 :揭开基线数据的神秘面纱
临床基线数据分析是医学研究中不可或缺的一环!✨它就像是一面镜子,清晰地反映出研究对象的初始状态,为后续的干预效果评估提供了可靠的参照系。在随机对照试验(RCT)中,基线数据的均衡性更是直接关系到研究结果的科学性和可信度哦~👩⚕️
🔍 基线数据的核心要素
- 人口统计学特征 👥
- 年龄、性别、种族等基本信息
- 教育程度、职业状况等社会因素
- 这些数据帮助我们了解研究人群的代表性
- 临床特征 🩺
- 疾病严重程度、病程长短
- 合并症和并发症情况
- 用药史和治疗经历
- 实验室指标 🔬
- 血液生化指标
- 影像学检查结果
- 基因检测数据(在精准医学时代尤为重要!)
📈 基线数据分析的黄金法则
统计方法的选择是基线数据分析的灵魂!💫常用的方法包括:
- 连续变量:均值±标准差 or 中位数(四分位数间距)
- 分类变量:频数和百分比
- 组间比较:t检验、卡方检验、Mann-Whitney U检验等
⚠️ 特别提醒:P值>0.05不代表"没有差异",只说明"没有足够证据拒绝无差异的假设"!统计显著性和临床意义是两码事哦~🧠
💡 基线数据的妙用
- 评估随机化效果 🎲
- 理想的随机化应使各组基线特征均衡
- 小样本研究中可能出现偶然不平衡(这时候就需要协变量调整啦!)
- 识别潜在混杂因素 🕵️♀️
- 通过多因素分析控制混杂
- 提高研究结果的内部效度
- 亚组分析的基础 🔎
- 根据不同基线特征分层分析
- 发现个性化治疗的线索(精准医学的曙光!🌅)
🚀 前沿进展与挑战
随着**真实世界研究(RWS)**的兴起,基线数据分析面临新挑战:
- 数据缺失问题更突出(需要多重插补等高级方法应对!)
- 异质性更大(但这也反映了临床实际情况呀~)
- 需要更复杂的统计模型(机器学习算法来助力!🤖)
🌈 :数据背后的生命故事
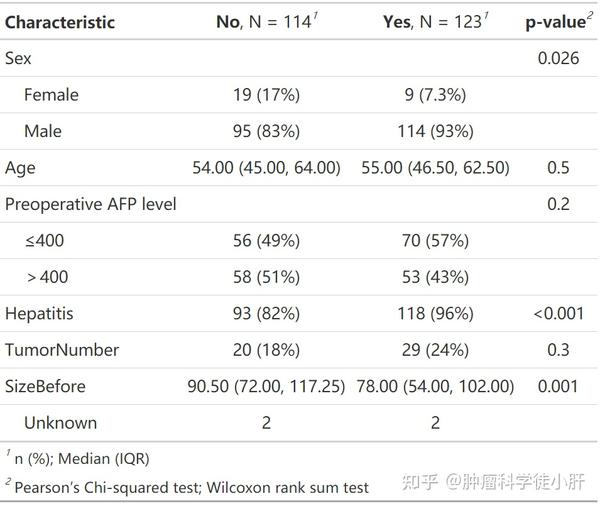
每一位患者的基线数据都不是冷冰冰的数字,而是承载着独特的生命历程和健康故事。💖作为研究者,我们既要掌握严谨的分析方法,也要保持对数据的敬畏之心,让统计学真正服务于医学进步和患者福祉!
💬 网友热评:
-
@医路向前:太实用了!作为临床研究生,这篇文章把基线分析的要点讲得清清楚楚,收藏学习!📚 #临床科研 #数据分析
-
@统计小能手:终于看到有人强调P值的正确理解了!很多研究者都误解了统计显著性的含义,作者讲得很到位👍
-
@未来医生:喜欢这种既专业又生动的科普!特别是最后提到数据背后的生命故事,让人感动~医学不仅是科学,更是人文❤️
-
@数据驱动医疗:真实世界研究部分写得特别好!现在RWS越来越重要,但基线数据分析确实面临新挑战,作者指出的方向很有价值!
-
@科研小白:作为一个刚入门的研究生,这篇文章解决了我很多困惑,特别是统计方法选择那部分,太有帮助了!谢谢分享~✨
百科知识





