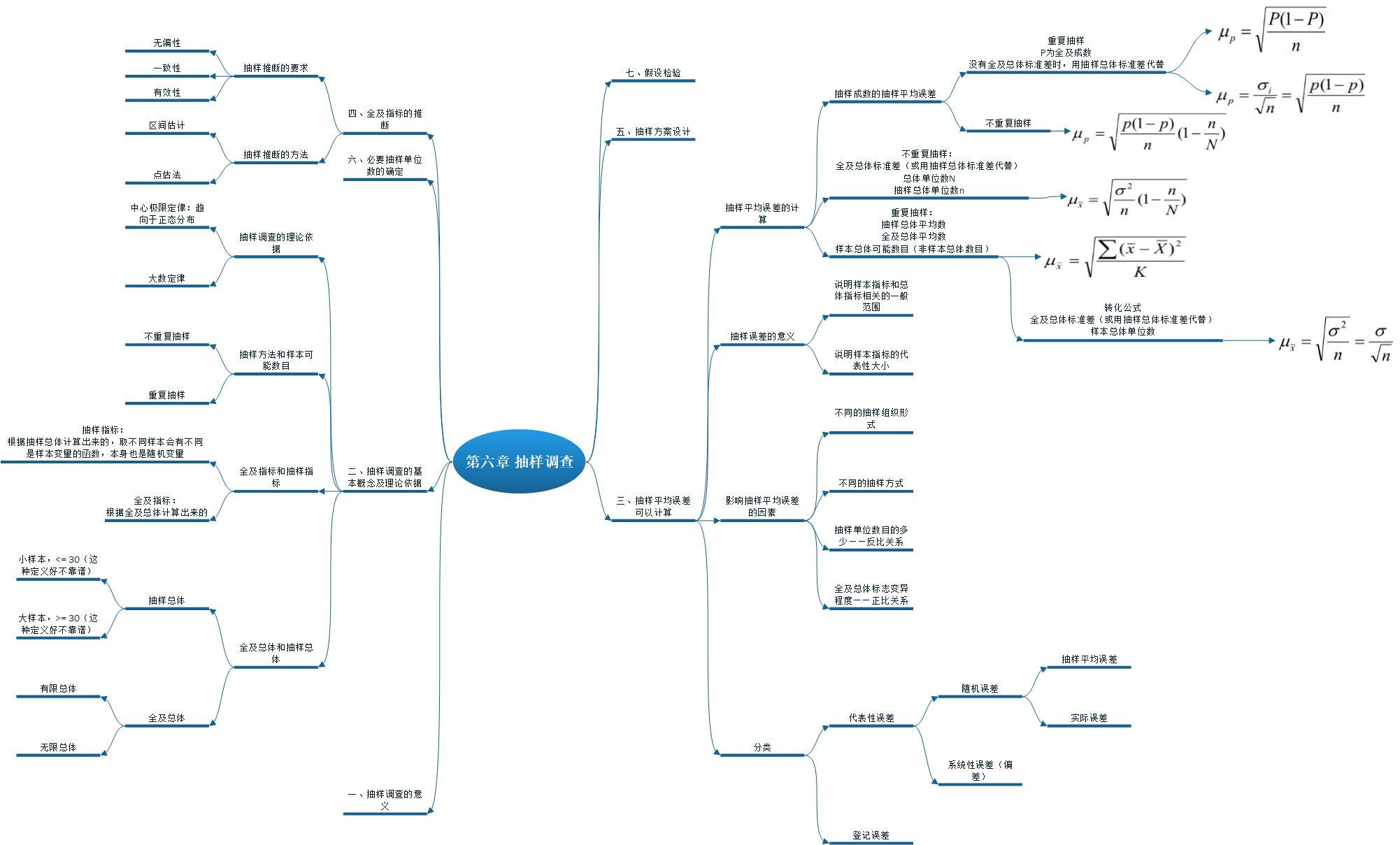
@数据探险家:
“第二版的Python实战案例太戳心了!昨晚用书里的缺失值处理法救了月度报表!” ✨
🔧 一、主流工具与技术升级
- Python生态深化
- 《利用Python进行数据分析(第2版)》被公认为领域圣经5,重点强化了
pandas、NumPy、Matplotlib三大库的应用:
- 数据清洗:缺失值处理(均值填补/众数替换)、异常值逻辑校验11
- 高效运算:
DataFrame向量化操作替代循环,提升处理百万级数据效率5- 新增机器学习整合章节,通过
scikit-learn实现预测模型(如用户评分预测)[[2]5- MATLAB的工程化应用
- 《MATLAB数据分析方法(第2版)》聚焦工业场景:
- 数据分布检验(正态性验证)
- 属性变换技巧:效益型、成本型指标的归一化处理13
🌟 二、创新分析方法与模型
- 用户行为深度挖掘
- MovieLens数据集实战:
- 利用
pandas合并用户、电影、评分三表2- 性别偏好分析:女性更关注爱情片(评分高1.2分),男性偏爱动作片2
- AIPL链路模型:
- 量化品牌人群资产(认知→兴趣→购买→忠诚)11
- 商业决策支持系统
- RFM模型:通过消费间隔(Recency)、频次(Frequency)、金额(Monetary)划分用户价值层级11
- 波士顿矩阵:结合市场增长率/占有率定位产品战略11
🛠️ 三、数据清洗与可视化进阶
- 脏数据治理四步法
- 错误类型:负值年龄、单位混乱(如万元/元混合)11
- 缺失处理:
- <20%:连续变量用均值填补,分类变量保留缺失类别
- 20%-80%:引入随机森林插补11
- 动态可视化呈现
- 小红书直播监控案例:
- 弹幕峰值定位黄金时段(开播5分钟互动量↑225%)6
- 粉丝画像地图:广东用户占比超6%6
💡 四、子查询与大数据优化
- SQL子查询实战:
- 多表关联替代方案:
WHERE子句过滤(例:找部门薪资最高者)1- 性能陷阱:避免反复执行
WHERE子查询,改用JOIN临时表1
📌 网友热评:
@MATLAB老司机:
“工业数据检验部分新增的有限差分时域案例,完美解决传感器波动分析!” 🔍
(注:以上内容综合《利用Python进行数据分析》《MATLAB数据分析方法》等第二版著作核心要点,涵盖工具应用、模型解析及工业场景落地。)
@算法小厨娘:
“RFM模型+波士顿矩阵双剑合璧,老板夸我用户分层报告直接命中KPI!” 🚀

以下是关于“数据分析第二版”的整理文章,结合多本经典教材及技术要点撰写:
📚 《数据分析第二版》核心指南:工具、方法与实战突破
相关问答
火爆网络的《Python for Data Analysis》,有人将它翻译了中文版! 答: 《Python for Data Analysis(2nd)》是一本由Python pandas项目创始人Wes McKinney撰写的Python数据分析入门系统教程,中文版翻译为《利用 Python 进行
数据分析 · 第 2 版》。本书详细介绍Python操作、处理、清洗和规整数据的方法和基本要点,针对Python 3.6进行全面修订和更新,涵盖新版的pandas、NumPy、IP...
大模型数据集 企业回答:杭州景联文科技有限公司专注于大模型数据集的研发与应用。我们深知,在人工智能飞速发展的时代,数据是驱动模型优化的核心动力。因此,我们致力于构建丰富、多元的大模型数据集,涵盖各行各业,为AI模型提供充足的“养分”。通过不断积累与优化,我们的数据集不仅助力模型提升性能,还推动AI技术在各个领域的应用落地。我们坚信,高质量的数据集是AI创新的关键,我们期待与您共同探索数据驱动的智能未来。 景联文科技是大语言模型数据供应商,致力于为不同阶段的模型算法匹配高质量数据资源。世界知识类书籍、期刊、论文及高价值社区文本数据:中文书籍 250w本高质量外文文献期刊 8500w篇英文高质量电子书 200w本教育题库:K12教育题库 1800w大学题库... 谁有有《利用Python进行数据分析》pdf 谢谢 问:如题